

GameBot's COTA Demo Showcases FPS Bots Powered by LLMs
In this sponsored episode we chat with the devs at Gamebot about their new LLM tech.


AI and Games is made possible thanks to our premium subscribers who pay to support our work. Subscribe now to have your name in video credits, contribute to future episode topics, watch content in early access, and exclusive supporters-only content.
If you'd like to work with us on your own games projects, please check out our consulting services provided at AI and Games. To sponsor our content, please visit our dedicated sponsorship page.
February 24th 2026 saw the release of COTA: a technical demo showcasing GameBot’s new AI bots that are powered by large language models (LLMs).
COTA, which stands for Cognition, Operation, Tactics, and Assistance aims to highlight how the developers have built an LLM-driven AI architecture that can reason on micro- and macro-gameplay levels, react to changes in game state, plan strategically to achieve tactical goals, and coordinate a team of both AI agents and humans in real-time. Though the real highlight, is that GameBot asserts that their solution gets around the latency problem, with the underlying architecture capable of coordinating all of these bots with a response time of less than 100ms.
For this edition I’m going to dig into how COTA’s underlying AI architecture works. With the demo now live for anyone to download and try out, we were invited to playtest a pre-release version to get an idea of how it all works, and put together some initial impressions of how it all plays in the moment.
It’s an interesting idea for sure, and I can attest that it works: the bots are fast, responsive and capable of playing through entire rounds of gameplay in ways that feel coordinated and sensible. But it feels like there’s still a bit of work to be done both in the quality of underlying behaviours as well as how this is all communicated to the user.
We’re going to dig into the underlying architecture of the bots and how they operate in action, plus we also had GameBot answer my questions about how this all works and what the future of this tech is shaping up to be.
Follow AI and Games on: BlueSky | YouTube | LinkedIn | TikTok
GameBot and the COTA Demo
So a quick overview of what the demo is all about before I get into the weeds of it. Built in Unreal Engine, this demo has you play a stripped down clone of Counterstrike’s Dust 2, and has players face off in a 5v5 game of bomb defusal - with the team of counter-terrorists defending their side of the map while the terrorists seek to plant the bomb and set it off to score for the round.
But the focus is on the bots you play alongside. In each round of the demo I was playing alongside four bots, against a team of five bots. However unlike a regular playthrough, I can observe at any time not just the strategy the bots are making, but deep-dive into their decision making, plus I am being told by the bots what to do in the moment. Given I’m part of the team, I am given instructions on how to proceed in ways that fit the broader strategy, and this updates and changes as the teams overall gameplay progresses. The devs are confident that this architecture provides a general purpose decision making framework that can adapt to different genres as well as scale to other game modes and situations.

The project stems from a company called GameBot, who have dev teams across North America and Asia, and have been involved in building bots for mobile games since their inception in 2019. The company has cut its teeth building AI bots for the likes of PUBG Mobile plus League of Legends: Wild Rift, the portable version of Riot’s beloved MOBA. These bots have ranged in their technical complexity but often using a combination of traditional game AI alongside supervised learning and reinforcement learning techniques - which is an increasingly popular approach to bots in mobile gaming. But this is the first time around - to my knowledge at least - that they have built a bot that is being driven by generative models.

It’s worth stressing as we move forward, that this is distinct from the MLMove project that we discussed late last year. MLMove was the use of a lightweight 21MB transformer - the type of neural network used for large language models - that sought to handle the movement for modded bots in Counterstrike by learning from data from esports players. COTA on the other hand is dealing with more than just the movement, it’s handling both individual actions and team tactics, while also recognising and responding to the player’s actions - and as we’ll discuss in a moment, it does so without the use of player data.

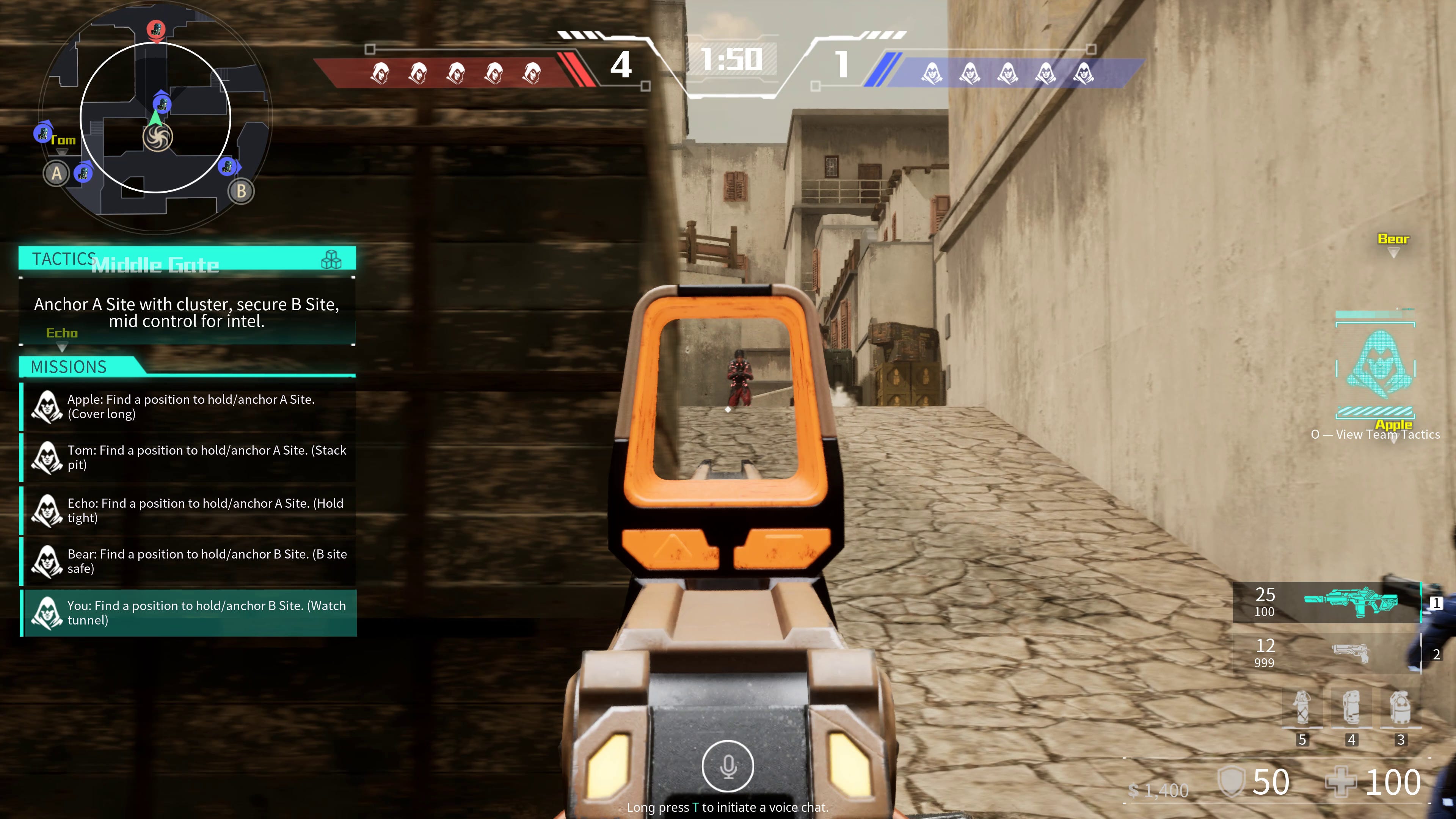
So let’s kick things off with a quick breakdown of what it’s like to play the demo, and what is happening under the hood as you play. As you can see in the image above, I can bring up a UI the left hand side of the screen what our teams strategy is - both the global strategy, as well as what my priorities are for the round. As the round continues, both the strategy of the team, as well as what individual team members should be doing shifts accordingly.
For this to work as shown, the underlying COTA architecture is running a two-tiered system, there is the commander layer, which is the strategic layer for all the bots, that is thinking on the global or macro scale. It’s assessing the map control, the intensity of combat, and potential strategy of the opposing team, all while analysing the overall status and health of your team. The commander will then dictate the overall strategy: are we going to attack a point, maintain control over a section of the map or rotating to another, or fall back.
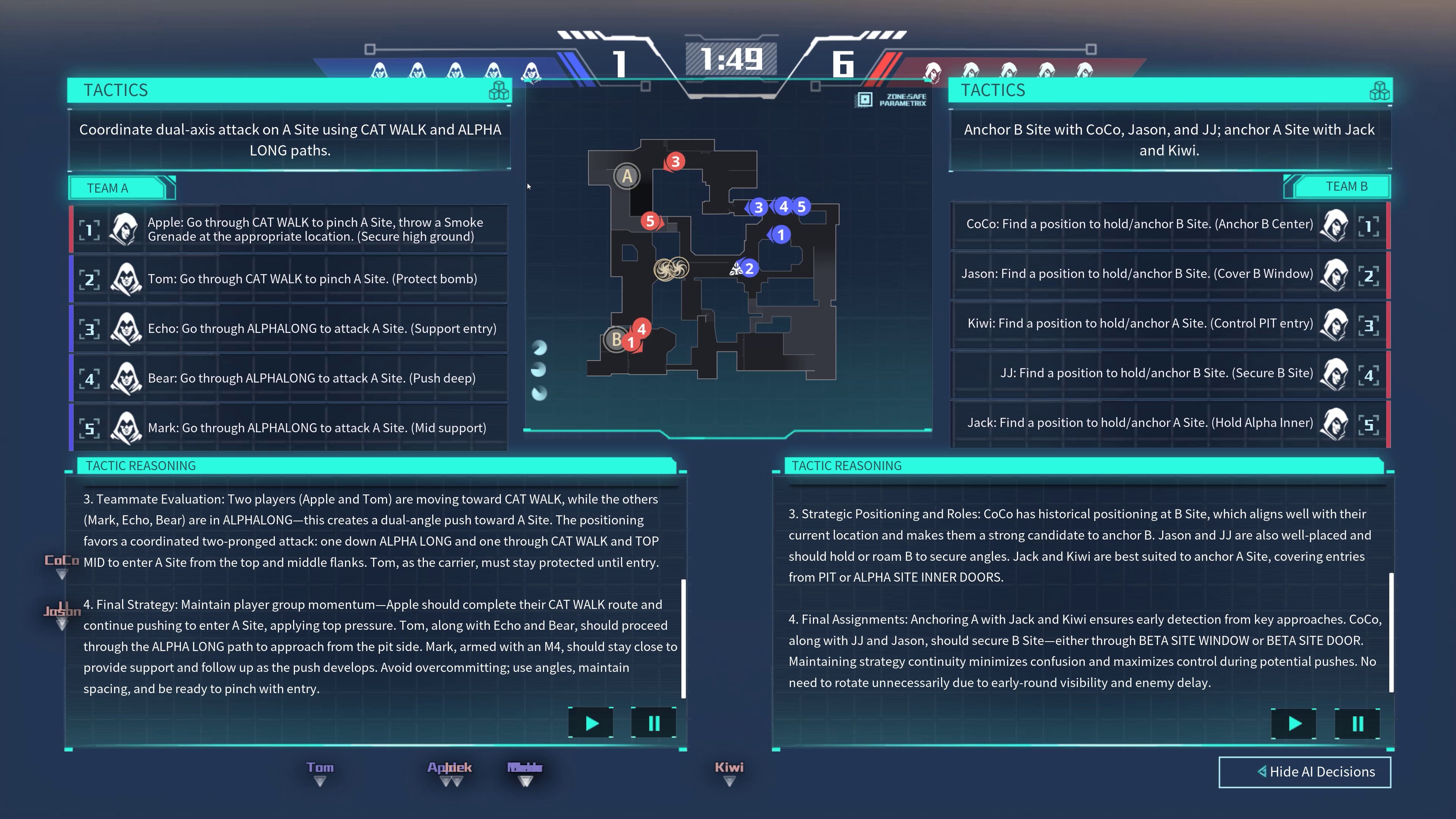
Then there is the operator layer: which is the individual bots. Each of the bots is focussed solely on their own individual behaviour in the moment: reading the game state to then decide how to move, aim, shoot etc.
Decisions from the commander layer are filtered down into a individual strategies for each operator. Meanwhile the operators acknowledge the strategy, and factor that into their decision making alongside how to create a movement path (deciding where to move towards and how to angle the view), alongside the contextual placement and actions such as firing or throwing grenades.
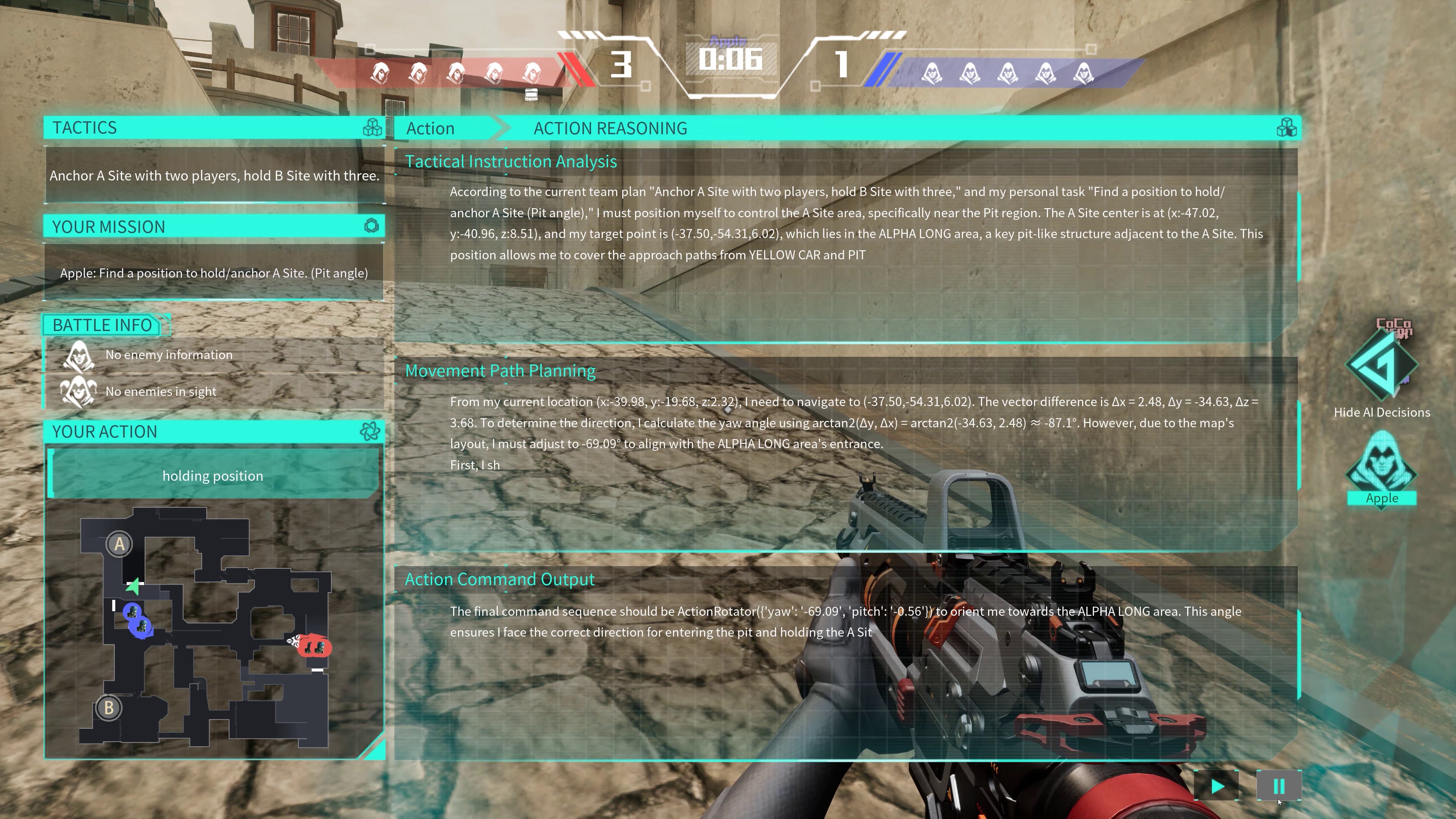
Now as you can see from the image above, the output of the LLM is a ton of text, but how does that turn into gameplay? Let’s go a little deeper into the tech stack.
The COTA Tech Stack
Given we mentioned it from the top, we know COTA is using Large Language Models, but I wanted more information on what’s really going on, and credit to GameBot - after I sent a stack of questions about the structure of input data, processing of game state, the training mechanisms for the LLM, the size of the model, the context window and prompting practices, and behaviour execution, I got my answers from the devs directly, with help from COTA’s project lead Mu Yang, who is also the director of algorithms at GameBot.

The first thing Yang clarified for me is the system is dual-layered, meaning it runs multiple models in the architecture. Separating the commander from the execution was a deliberate decision given LLMs historically have been shown to struggle with handling macro and micro behaviours in parallel. Hence having the commander do the big thinking while the operators acknowledge this in their own behaviour seems like a natural fit. This also helped keep the 100ms limit on reasoning that the team had planned for, given this was considered an acceptable timeframe for fast and responsive behaviours.
But how are these models are trained? As I mentioned earlier MLMove was achieved by pulling down scores of data from professional players, but COTA is running this entirely without user data. First up, the Commander needs to have a broader understanding of how the game plays, and be capable of processing information about the game state effectively.
Mu Yang: We ran extensive internal tests and found that an 8 billion parameter model is the right balance [totalling 16.5GB in disk size]. It’s large enough to reason and understand the complex situations. We begin with supervised fine-tuning, or SFT. Based on prior commercial projects, we built a data synthesis pipeline to generate gameplay samples. Each sample contains a game state, a text instruction, and a game action. A subset of this data is annotated with chain-of-thought reasoning. We then apply GRPO-based reinforcement learning on the remaining data. We created rewards for action correctness and output validity. Finally, we used reinforcement learning from human feedback to align the commander’s decisions with human intent.
Meanwhile the operators require a similar but different approach, given they need to have clearer understanding of the rules of the game, such that they stay on target and on point.
Yang: The operator follows the same overall training structure, producing a ‘teacher’ model we call ‘Operator Thinking’. Operator Thinking receives richer inputs than commander, including first-person visuals, map information, game rules, and high-level instructions from the commander. Its output includes both reasoning and the textual action descriptions. At this stage, the model demonstrates strong generalization and can adapt to new maps or rule sets.
So as Yang described, the original operator model is capable of making intelligent decisions about what to do in the moment. But the thing is, it’s too big. Hence as described, this first operator model is what is known as a teacher. GameBot then use an approach known as the Teacher-Student model, also referred to as knowledge distillation, where a smaller version of the model - called the Student - is trained by distilling down the information in the original teacher model into something smaller.
This modified student model also has game rules and map knowledge being mapped into it directly, alongside compressed state descriptions and a game specific action head to the attention layers to help with multi-action execution. So while distilling down key information from the original model, plus making these additional tweaks, it means it can make decisions within the 100ms limit.

Now what you see in the commander and operator UI layers is the outputs being generated by the LLM. This is being fed from information from the game state, and then it’s being processed. Each operator is gathering information from the current frame using traditional game AI methods such as environmental queries about whether they can see opponents, as well as basic information as to their current position and movement and status. This character-centric approach prevents giving bots any information from the game state they should not have in the moment. This is then translated into a text-based prompt that is fed into the LLM, and what you’re seeing in these overlays is the output. This text is then parsed and translated into actions in-game, and this is all being done server-side behind layers of security to prevent it being manipulated.
Yang: All inference runs server side. The operator runs on the server, and its actions are sent directly to the game server. Both systems run in the same server cluster to minimize latency. There are no predefined behavior scripts. All actions are generated by the model itself.

Our First Impressions
Having spent several hours playing through the COTA demo over the past couple of weeks, it really got me thinking about on multiple levels. The efficacy of the tech: does it actually work in context? But also how does it feel to play a demo where I am working these bots, and am also - to a certain degree - having my behaviour governed by one.
I’m left with some mixed feelings about it. For one thing it is technically impressive. The bots do work: the team are executing entirely via the LLMs. There is a sense of overall collaboration, they react to changes in the game state, they are capable of acting in the world in ways that make sense the majority of the time. Outside of a few hiccups, the performance of the game was generally quite smooth, and I didn’t notice any impact from the LLMs on the server running their inference. However, there are a number of qualitative factors to consider, both in the performance of the bots as well the way in which this is integrated that make it difficult to enjoy the demo itself.
Strategically the commander is capable of both devising tactics, breaking them down for individuals, reacting to changes, and then reformulating the plan in real-time. This was interesting to observe as things changed, during a round, as well as having it observe what I do. After all I would sometimes follow orders, and other times just ignore it - or actually fail to understand what it wanted. It’s capable of reacting to this accordingly - though sometimes I noticed it just doesn’t give me anything to do? Perhaps it’s just fed up with me. Admittedly it was more fun to watch teams of bots go at it against one another. It strikes me that could be a game mode in and of itself if you can feed your ideas to the commander.
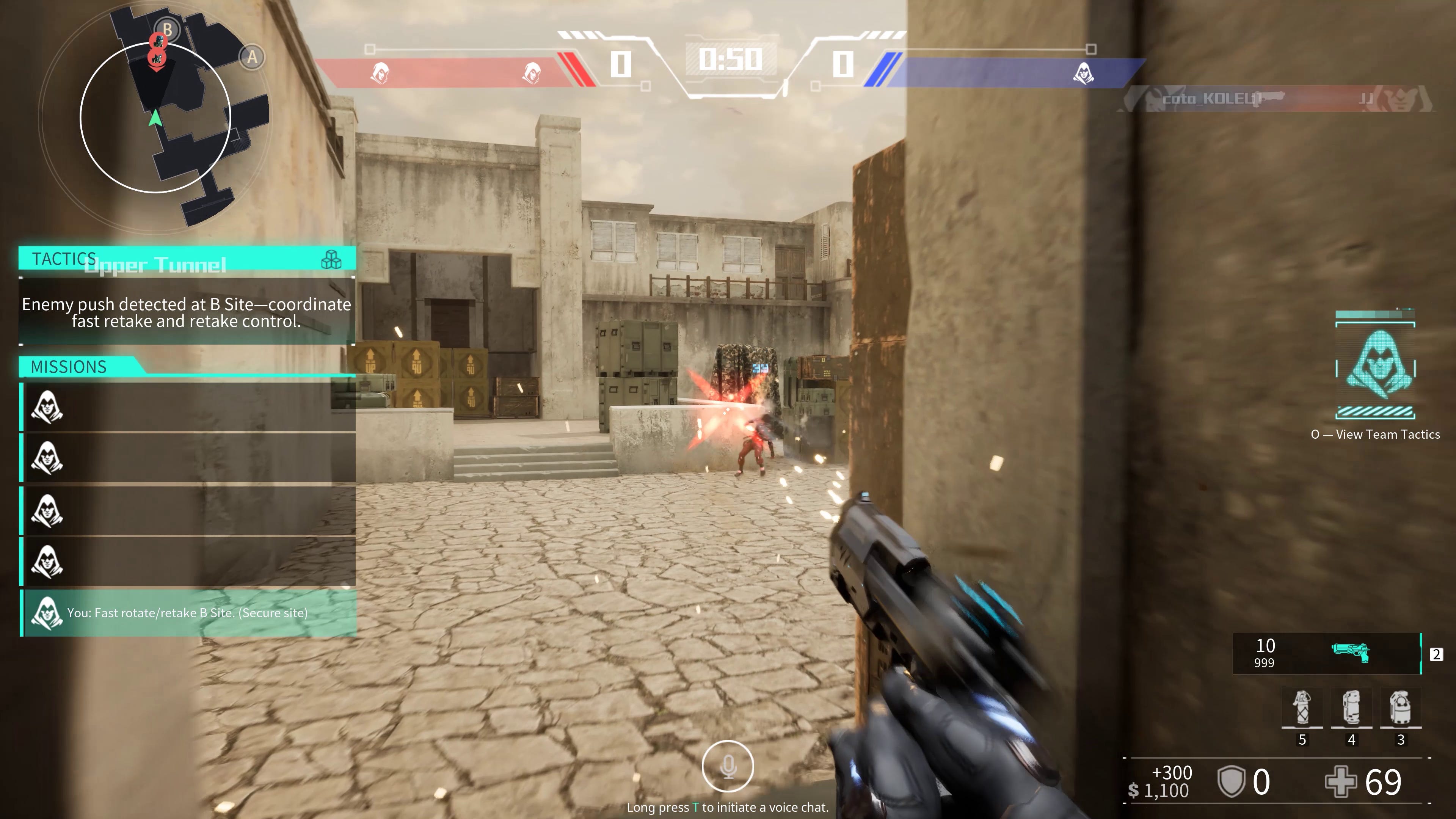
Though I noticed several times that it employed some... questionable strategy, or felt repetitive. Far too often the strategy as an attacker was to push up on Alpha by splitting the team between ‘alphalong’ and ‘catwalk’. We very rarely, if ever, attacked Bravo. Meanwhile it feels like there’s a need to dictate to operators the level of urgency with which the commander’s strategy should be executed, or by having more global state knowledge. I watched as my team lost several rounds where we either failed to catch a defender defusing the bomb, took too long to rotate given they would go all the way back to spawn, or in some instances failed to defuse the bomb in time despite us having control of the point, and the opposing team was all dead.
I do think more could be done both in the movement and in the final execution layers. Given I would see bots bunch up turning corners or entering areas of the map, making it all too easy for them to get wiped out. Meanwhile I noticed in spectator mode that a lot of bots take shots when they’re behind cover, or have their view either lurch around, or snap to an enemy’s location too aggressively. The latter is certainly a difficulty feature, but a lot of this could be refined by building more fleshed out behavioural macros that the LLM outputs could be processed into.
Ultimately for me, the big problems with the demo - which was addressed to some degree during the preview window - was the lack of UX design surrounding the bots. This isn’t a generative AI problem, it’s a game AI problem - and if you’ve followed AI and Games for a while, you know how often we talk about using additional flourishes in art, animation, UI, and audio to help communicate the behaviour of NPCs - and for me a lot of what would really help sell these bots is currently missing. Naturally of course this is a demo about the tech, but I don’t think you can sell one without the other, and so I want to break down what was perhaps for me the biggest hurdle I had when playing.
As you’ll have noticed throughout, there’s a huge amount of text on screen, be it the global strategy, or my individual actions, and those of others. Even when it’s just the immediate actions sent to me by the commander, it relies on a lot of built-in knowledge about the map design and even some terminology about what I’m meant to do. Of course I’m going to learn that over time (and I’m not a Counterstrike player so it did take minute) but the issue is I have to stop looking at the centre of the screen - where the action is - to focus on text coming in via a text field. This also updates frequently and trying to read all of that while in the thick of combat is a big ask. For me this can be mitigated in a number of ways:
Adding voice lines and barks for the bots and the commander.
Having the UI and HUD highlight where I’m meant to be going.
Simple UX cues to indicate whether I’m operating in line with the intended strategy.
During the preview window the demo was updated to include barks - which for those unfamiliar is a way to communicate information in a condensed format - and while it’s going through a text-to-speech pipeline that sounded pretty rough, it already made a huge difference. Suddenly having a lot of game state information - and the intended actions of the bots - be condensed into short audio soundbites was really useful. I could just listen to them speak to me, and then react accordingly. The thing that’s now missing is having the commander clearly tell me whether I’m adhering to the strategy or not, given I would rather not have to focus too much on that text field.
The most recent version also includes the ability to speak into the microphone, where I use a speech to text pipeline to communicate with the bots. I sadly didn’t find much value in it, given I didn’t really feel like anything I said was having any material impact. I would try and share information about my current strategy, where I spotted targets and ask for what to do. But I never really felt like this input had value, nor were they really responding to me. I will stress as well I don’t enjoy talking to NPCs, given it adds an additional level of cognitive load where I had to think about not just what I want to say, but how I say it such that an AI bot will interpret it. After all first it has to get past my Scottish accent - and I noted several times the speech-to-text only understood half of what I said, but also I have to make sure I’m having to think of how to express this information such that the LLM will process it. This was a similar issue that I had not that long ago when Ubisoft invited me to try out the Teammates demo - which I wrote about in our weekly newsletter over at AIandGames.com. So it’s not necessarily an issue specific to COTA, but rather a problem that this type of game design will have to reckon with in the future.
For me it’s about doubling down on the UX design, particularly in audio barks and the HUD. If the devs can work through that, then it could really add value to the player’s experience.

Closing
So that’s the COTA demo for you. As mentioned earlier the project is out now, and it’s free to download and check it out. I’ve spent a few hours with it over the past couple of weeks, and I started getting more adventurous with it over time. Plus GameBot are encouraging people interested in the project to join them in their Discord server to share your thoughts and give feedback on the project. Links are at the bottom of this article.
Check out the COTA demo at:
https://gamebot.ai/product/cota-apply?channel=kl_01Visit the GameBot Discord:
https://discord.gg/vWrGCHGsKc
A thank you to GameBot for reaching out to us try out the project and collaborate on this issue, and for taking the time to answer our questions as well. It’s nice when we get to ask more technically complex questions to the PR team and then the devs answer them for us. It’s very much appreciated.