

MLMove: The LLM Trained to Play Counter-Strike
We chat with Dr David Durst about his PhD project to train a 'language model of movement'

AI and Games is made possible thanks to our premium subscribers. Support the show to have your name in video credits, contribute to future episode topics, watch content in early access, and receive exclusive supporters-only content on AI and Games.
If you'd like to work with us on your own games projects, please check out our consulting services provided at AI and Games. To sponsor our content, please visit our dedicated sponsorship page.

These are AI-controlled bots designed to play Counter-Strike. But they’re unlike any other bots that you will have encountered. They move against walls and other geometry to block enemy line of sight. They push up when defending a bomb to stop it from being diffused. They establish and apply pressure on known choke points. They even know how to flank enemies, such that they can attack in a coordinated fashion.
Their secret is they’re trained to develop intelligent, coordinated movement, and they do that by using the same AI technology that powers large language models.
In 2025, the conversation around generative AI in the video games industry is about the impact it can bring in various aspects of production. Many studios are exploring whether production costs can be minimized through use of image generators and large language models, with much debate around the impact this has on game developers’ livelihoods, the quality of the finished product, and the appetite from consumers for games that use AI-generated content. But outside of conversational non-player characters, we’re not seeing many examples of what this technology can do that brings value to players, and that’s where this project comes in.
For this episode, we dig into the MLMove project: a concept that shows not only you can use generative AI to improve the experience for players, but you can do it in a way that is completely antithetical to the trends currently running in generative AI.
We dig into the research to find out more about how it works, plus I sat down with the project’s creator, Dr. David Durst, to find out about his experiences in building it, what his ambitions were in creating the MLMove bots, and what potential this has to be adopted in commercial games moving forward.
Follow AI and Games on: BlueSky | YouTube | LinkedIn | TikTok
What is MLMove?
MLMove is an AI bot designed to play Counter-Strike by learning against professional human play. While it’s comprised of a number of systems, with the actual combat handled by a traditional behavior tree, the focus, as the name implies, was on building the movement component of the bot, with the position and orientation of all characters on a given team controlled by a generative AI model.

Published at the 2024 Symposium on Computer Animation from a thesis supervised by Pat Hanrahan and Kayvan Fatehalian, MLMove was the final project of David Durst’s PhD, which he read at Stanford from 2017 to 2024. I had the pleasure of meeting David for the first time at GDC about a couple of years ago, where he was telling me about his research, and we’ve kept in touch since. And with the project complete and the doctorate in the bag, I was keen to find out more about how this project had come about, and why Counter-Strike was the game to try it out in.
David Durst: So my PhD was a little bit of a winding process, and I had come in as a database person: done a rotation with some database professors and really enjoyed that, and then I pivoted to doing programming languages for computer architecture, uh, because it seemed like a very interesting field where you could do a- have a lot of impact. And I had this really great paper where I published some really cool results on type theory for designing computer chips, and I realized through that that a lot of the great progress was actually gonna be made on the application side, that, like, hey, you could build these fundamental chips, but if y- a lot of the, like, you know, 10,000 x, you know, order of magnitude changes come from building an application-specific solution rather than like, a general purpose chip.
It’s hard to beat NVIDIA. You don’t wanna be in the business of competing with NVIDIA.
So I was looking around for applications and datasets where I could really be the expert, and could both be the technical person and the expert.
Tommy Thompson [AI and Games]: Did you go looking for it because you’re a CS fan originally? Like, what was the relationship there?

Durst: My advisor’s first suggestion was basketball. Like the [Golden State] Warriors are fairly analytics heavy. I spent time looking at basketball, and there was this problem that the data’s really hard when you have to deal with perception. You, you know, you, we wanted to get perception out of the loop and deal with the situation where you could just read the state. Because, like, in a video game, it just seems odd to use a camera to perceive things when the engine knows what’s going on, and there are a lot of great AI groups doing perception work.
So lo and behold, you find HLTV. You find all these great demos. There’s a wonderful community of, of, of people who have demo parsers [like] the GoLang Demo Parser. They’re a wonderful community of people. And it’s like, great, okay, so we have this amazing data source of humanlike behaviour. What can we do with it?

And so I spent a lot of time trying to find cheaters, ‘cause as a gamer that’s the first thing you wanna do is, like, find the cheaters, right? Or, like, find the network bugs. These are all the issues. But the problem is that, like, finding cheaters is very, very difficult. It’s sort of a problem of finding the outliers. And I did this analysis where I looked at reaction times, and if you define reaction time as time from any visible until time when any crosshair is on them, um, and this is pre-publication, but very dirty data.
I sort of measured my friends with cheats on in Counter-Strike where they have a mode on where you can see the wire frames. Not actual cheats, but they have a mode on where you can turn on wire frames, and you can sort of pretend to cheat. And you compare that to pros, you see that pros actually look like they’re cheating in tournament. They’re clean, they’re legit, but because they’ve played so often, they’re predictively aiming where people will be, and their crosshair is actually on the enemy, like, 100 milliseconds before they’re visible.
It’s sort of like [what a] cheating amateur looks like. And so it’s very hard to detect these subtle things. And so I realized is that the real key is that if you wanna understand these complex human behaviors, you first need a model of human behavior. And then you can use this model to do really interesting things.
A Change of Approach
It’s worth taking a moment to highlight what this is doing that’s different from traditional game AI. Typically, we rely on navigation meshes to move characters around in a 3D environment, a point we’ve discussed in both the AI 101 episode on the topic (see below). But also, we’ve dug into specific challenges faced in games when handling navigation and complex environments such as Sea of Thieves, Horizon Zero Dawn, and Death Stranding.
However, while navigation meshes are complex and intricate systems, they’re not built to support this level of spatial awareness out of the box. You would need a lot of tagging in the gameplay space and a custom navigation and path following system set up to have characters move around like this. Plus, hugging the edges of the navigable space and pushing right up on cover can often be difficult for an MPC, given we typically don’t bake the nav mesh to be exactly the same shape as the geometry, but rather carve a shape that is going to be useful for gameplay.

So MLMove is trying a different approach by training a model that simply learns how to move in the map based purely on how humans themselves move within it, and it’s achieved using what is known as a transformer, which we typically use for large language models. One of the most interesting things about MLMove is it takes an inherent trait of how transformers work. That is both why large language models have proven to be quite powerful, but equally is the reason they can often be quite frustrating.

To summarise, transformers are the neural network architecture that learns contextual relationships within the data that it’s trained on such that it can take an input and generate an output that is likely given their contextual relationship. We typically think of transformers as language models such as GPT, Gemini, and Claude, which learn relationships between words and their training data such that you can ask it a question in human language and it can generate an answer.
Notably, it doesn’t learn the meaning of the text, but rather how words and concepts relate to one another, and as such can generate answers that quite often make sense until they come under further scrutiny. This is why LLMs are prone to inconsistencies in simply making stuff up, what is typically referred to as hallucinating, because the LLM is simply predicting the next word it should write based on the input, the current state of the output, and what it learned from the training data. It doesn’t understand what you asked, nor does it understand the answer it gave.

It just predicts a sensible response. While this is frustrating with language models, this is actually a useful feature for MLMove given it can pretend to move a team of MPCs around in a way that’s reflective of how a human team of players might operate, even if it isn’t 100% accurate. To quote the MLMove research paper:
“In an FPS game, human players not only have a complex action space, but also demonstrate complex inter-player interaction and coordination that are quite challenging to model in a rule-based system. However, recent work in transformer models show how to imitate the effect of complex human decisions and interactions without modelling the intermediate steps or decisions that led to the final actions.”
Learning to Move Like Professional Counter-Strike Players
David Durst, Feng Xie, Vishnu Sarukkai, Brennan Shacklett, Iuri Frosio, Chen Tessler, Joohwan Kim, Carly Taylor, Gilbert Bernstein, Sanjiban Choudhury, Pat Hanrahan, Kayvon FatahalianSymposium on Computer Animation (SCA), 2024
So by modelling the data of human players, it gets to the end result of their behaviour, having observed thousands of instances. And while it doesn’t understand why human players make that decision, it does give us an end product that is nonetheless quite convincing. This is largely because the problem is very tightly scoped.
Durst: So the first version of the bot I built was purely running off the nav mesh. You can parse out the dust to nav mesh, and you can run on it. And I put that onto Reddit, and people loved it. But the problem was in order to get it to be really human-like, I had to hand annotate where to stand. Um, because people don’t just follow nav mesh. Pros, like expert players, stand in very specific places that have developed over decades. They form a- you know, they find ambush locations. They know the exact corner and the right m- person on the corner to do it. And there have been other people who have built bots for Counter-Strike that do similar things and they sort of always You take the nav mesh, and the nav mesh gets you to the, you know, like 10%, and then like hand-labelled points get you to like 50%. But then you have 2 remaining problems.
A, how do you transition between those hand-labeled points? You have this now complex finite state machine, when do you transition between them? And B, when you’re transitioning between them, how do you stand relative to your teammates? Like, you can build one bot that just goes from one to the other, but like, oh, like, I’m holding a forward aggressive point. When do I rotate back to the site to help my teammates?
And when I do that, how close do I stand to them? Because t- the closeness to teammates depends on factors like map geometry. And so And then also how much you sort of jitter around in a human-like way to be unpredictable. ‘Cause like in Counter-Strike, you know, movement d- impacts accuracy, and you always wanna sort of shoot at the apex of your movement so your velocity is zero and your accuracy is maximized. But humans aren’t perfect, so how do you sort of model that process of, like, you know, managing velocity and, and hardness to hit and accuracy?
And so what we came up with, was let’s just think of predicting the next keyboard state. Humans roughly move at about 100 milliseconds to 200 milliseconds, there’s some great literature on that, and you can sort of think of the brain as sort of a pipeline processor that, processes 100 milliseconds and then acts on 100 milliseconds.
And so we can think of this as, hey, just predict what the keyboard state will be over the next 100 milliseconds.
As Durst explains, this transformer model, a ‘language model of movement’ if you will, is being trained solely to run on the Dust 2 map, and he specializes the model to only work on Dust 2. While your first instinct may be to build the model to handle all maps in Counter-Strike, in this case it actually makes sense to specialize the model to a single map given professional players learn multiplayer games by repeatedly experimenting with strategies to fit a specific level. As such, he’s training an AI model that reflects human behaviour.

The CSKnow Dataset
In order for MLMove to be trained, you of course need some data. This led to the creation of the CSKnow dataset. While there are existing datasets on Counter-Strike for learning the game, they’re not necessarily focused on learning the movement of each player. To that end, Durst curated a dataset of around 1100 hours of play on Dust II, and then reduced it down to 123 hours, with a focus on 17,000 rounds of retakes, the custom mode where 4 offensive players have 40 seconds to retake and defuse a bombsite with 3 opposing players defending it.
Tommy: What was that process like in kind of curating that data and getting it ready for what you needed?
Durst: So we initially pulled down actually, like, mor- more than that. It was like I forgot the exact numbers. This was li- I think this was like 2,000 hours, it was like a thousand or 2,000 hours. This is like- Those are rough numbers. Um, of data, only on Dust II.
You know, trying to be very nice, not, not annoy anyone, just, just pulling down a thousand or 2,000 hours and try to be super clean about it. Um, uh, and then we n- you know, there, when I was looking at it, there’s a lot of noise in there. You know, like warmup rounds, bathroom breaks, you know, like guys running around with their knife out just sort of, like, knifing the wall- because, like, you know, they’re pros. They got 50,000 hours. Like, it’s a random warmup round in a, before a m- before a match and they’re on stage. They’re just messing around.
Um, and so you have to sort of A, build a str- parser that can sort of hope to get out the overtimes, you know, get the bathroom breaks out, those sort of things. Uh, and so first we cut down just to, like, the actual gameplay. And then the thing is, even in the actual gameplay, we wanted to focus on learning movement separate from a lot of the other strategy. How to do some of the, like, economy management, early round exploration. And so we’re actually fa- focused on a simpler sub-problem of just the retakes mode, so just when the bomb is planted.
This sort of makes things nice in that there’s always a clear objective to travel to, and you don’t have to worry about longer term, like, “Well, what’s my objective?” ‘Cause navigation is sort of a different problem from, “Should we attack bombsite A or bombsite B?” And so by taking retakes- Yeah. we sort of have that, uh, uh, isolated out.
The final dataset used for training is comprised of game information that includes:
Each Player’s ‘State’
Player position
Current velocity
Team ID
Status (alive/dead)
View Direction
Health
Armor.
Current Map State
Bomb Site Status
Time remaining on clock
All Events Since Last Timestep
Gunshots
Damage Taken
Player Deaths
This data is captured at a rate of 16 hertz, meaning it’s recording the player data 16 times a second, or every 62 milliseconds.
Durst: So, so the first version of the bot was like, ‘let’s just build something state of the art’. So I built a fully handcrafted behavior tree that plays Counter-Strike, controls both teams and plays Dust II retakes with my hand-labeled positions and I put it on Reddit and people liked it and said it was great. They said there were a bunch of problems with it, but hey, it was a lot better than the bots that ship with Counter-Strike because of course, you know, they have to play on every map and I just play retakes on one map.
So I obviously solved a much simpler problem. It’s not fair to compare them. Then I was like, “Well, what, what do people complain about the most?” And at least on the Reddit posts, the thing that they seem to complain about the most, and the thing I honed in on first was actually the mouse model. And I spent a lot of time, I spent like 3 or 4 months actually, on a failed SIGGRAPH submission, on a mouse model.
So literally, like, state of the world, predict their next mouse position, and that failed. It did okay when the target was standing still. It actually looked really human. It would sort of overshoot and come back and correct. But when the target was moving, it had never seen in the data examples of bad sprays ‘cause it was all looking at pros, so it never knew how to recover from its mistakes.
So the idea was we have this whole architecture [but] you don’t wanna learn everything. Learning everything from scratch in Counter-Strike seems really hard. Let’s learn the components that are challenging. And so the movement model is just a node in the behavior tree. A better version of this would have it run on a separate thread, but inspired by Unreal where to keep things simple, the behavior tree’s a single thread.
Designing the Counter-Strike Bot
With the data in place, the next step is to build the MLMove bot. The model is trained in a two state process:
A per-player embedding network converts the input of each player into embedding tokens that the transformer can process.
The tokens are then passed into the transformer to understand and interpret the current state of the game. This, of course, then helps it to predict the next outcome.
The output of the model is broken into a probability distribution across 97 possible configurations of decisions it can make in the game, and then decisions are then made by sampling from it. These decisions cover movement in 16 angular directions and at 3 different movement speeds. Plus, whether it should jump or simply stand still.
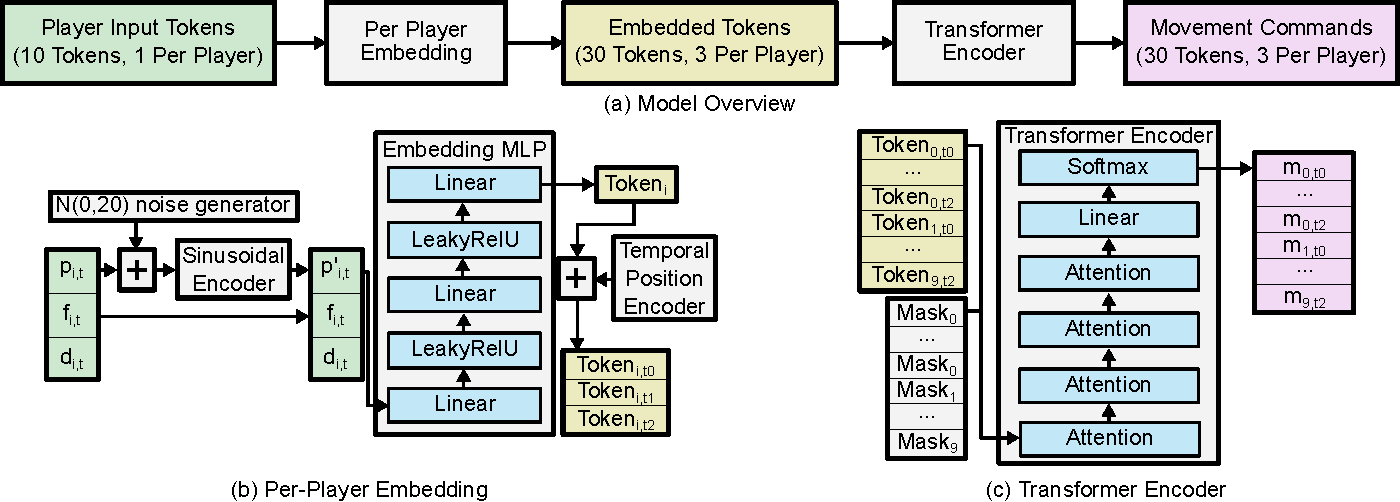
Now, the interesting part is that every time it does this, it also generates the output 3 times.
The first for right now at this exact timestamp in the game.
Plus it predicts what the agent should do 125 milliseconds in the future
And again for 250 milliseconds in the future.
The reasoning for this is that it helps prevent the model repeating actions, plus it helps it to understand the need for consistent behavior that flows towards desirable outcomes.
Evaluating the Bot

Having built the bot, the next big question was whether or not it actually succeeded in its goals. Durst conducted a study by recording video footage from replays of four different types of player in matches of CS:GO:
Regular human players
The MLMove bot
A rule-driven bot using the navmesh - designed by a skilled CS:GO player
Lastly, the default game bot that ships with the game.
To run this, Durst then pulled in a range of evaluators with either little to no experience in Counter-Strike, alongside others who were supreme master first class and global elite ranked players. The study was to evaluate which bots behaved the most human-like.
The results scored MLMove as the most realistic bot, with written feedback suggesting it showed a lot of traits common in human play, be it trading in a skirmish to capitalize on an enemy killing their teammate, avoiding gunfights in open areas, and holding high ground and defensive positions. This didn’t mean they were perfect however, given there was still some issues with jittery movement and sometimes lacking the necessary aggression to support a teammate as they pushed forward.
Tommy: What did you take away from that process? ‘Cause it seemed as if you were getting a lot of really interesting insights from them about things that they were seeing evocative of their play, but also things that maybe weren’t quite the same?
Durst: The first thing I was surprised by - before we got into what they did - was how excited people were. I would just say there are some really smart people out there who know a lot about Counter-Strike and, and can put together some very coherent discussions of what’s good and what’s bad.
Yeah, we saw some good examples of ‘trading’ like, you know, killing an enemy where, where the enemy’s distracted. But, like, sometimes for example, the bots were way too aggressive or not aggressive enough.

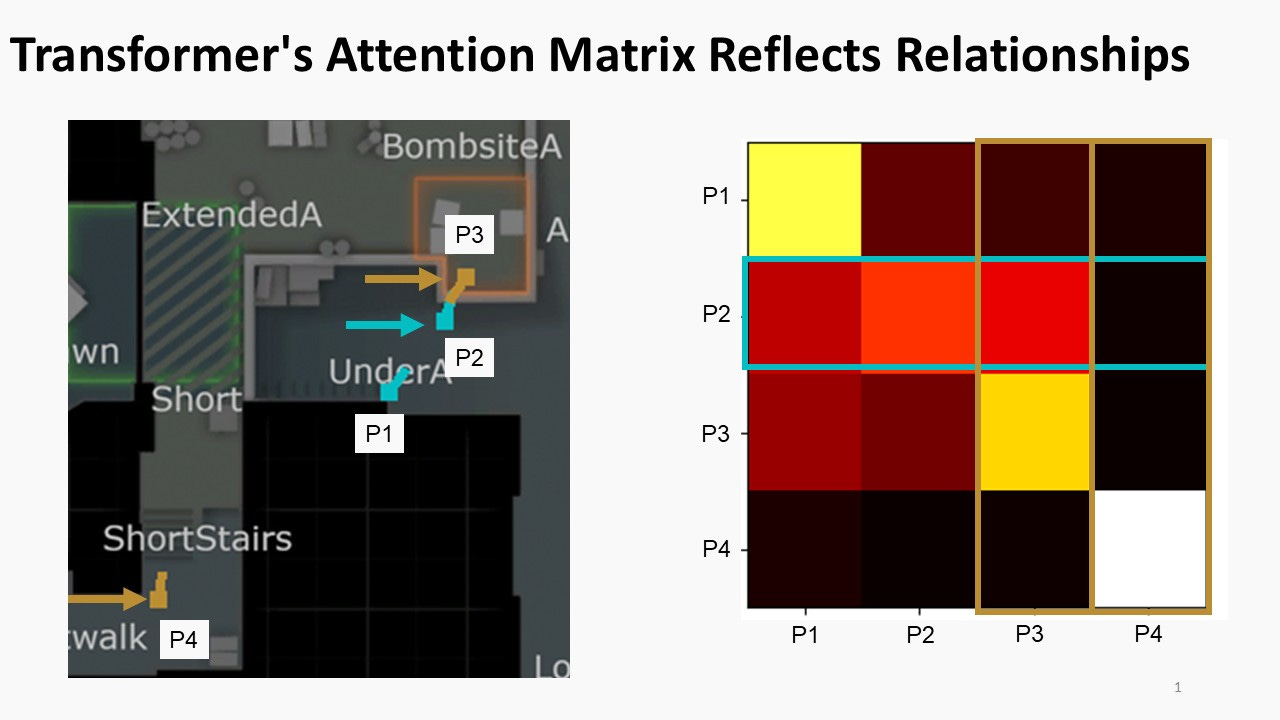
The things they would see were like, one [bot] would move in too fast and outrun his teammate. And, this is sort of the thing where you can actually, inspect the attention layer [of the transformer to see what’s happening[. One of the cool things about using the transformer in this manner is that you can actually see what tokens are paying attention to other tokens.
So in a language model this means what words are related to each other. In a movement model this actually means which tokens does the model think are important for the other token to govern its movement? And so you can sort of inspect, who do we think is paying attention to whom?
But I’d argue the most critical aspect of this is that the model is so small it could conceivably be deployed in a commercial game.
In an age where generative models that are being sold both to consumers, as well as the games industry, often carry billions of parameters, and then need to be hosted on cloud servers due to the need for gigabytes, if not terabytes of memory to store them, MLMove requires 21 megabytes of memory.
That’s right, I said 21 megabytes.
The generative model is comprised of 5.4 million parameters and was trained on a single desktop computer. With that setup, you could train a version of MLMove in around 90 minutes. When you combine this with the performance of the model, with inferencing for all players taking less than 0.5 milliseconds per game step, you have a generative AI system that can successfully generate a meaningful and practical output for use in a fast-paced first-person shooter.
In theory, a game studio could build a system like MLMove, deploy it in their game, and it would have negligible effect on the technical requirements for the player to run the game. Heck, you could run it on consoles without any issue, which is all the more impressive in 2025 when most generative models could not be deployed on Xbox, PlayStation or Switch 2 without impacting available video memory, and in turn, visual fidelity.
Tommy: Coming back to your earlier point, you said specifically about wanting to build an application. To show the relevance and value of this, and I think that’s the thing that really caught my attention going through it - you want this whole thing to be able to run on a single CPU core, rather than having it run on the GPU or in the cloud. Was that always the goal? To have that feasibility aspect?
Durst: So this is sort of one of the key surprises [for us]. We came in thinking, you know, ML’s big, ML’s expensive, and this a thing you hear in the gaming industry. Like, modern machine learning is like ChatGPT. It’s this big, huge thing and you need, like, a nuclear power plant to power it. And when you start looking at these models you realize they’re solving a very general problem that’s very hard. And when you start getting application-specific, the problem can get much easier.
The trick with a lot of these is, how can I make this as easy a problem as possible? And sort of the hard part is making the problem easy. So, if we’re just doing movement on one map, the problem becomes a lot easier. Now, sure, when we started I thought, you know, we’ll need these huge amount of GPUs and certain people sort of told me this was just, wasn’t gonna fly.
You know, the economics would look very different if every time you connected to a first-person shooter title you needed a GPU to back that server instance, you know? The economics would change drastically.
So okay, let’s see what we can do. Let’s try and get the model working and, you know, we were just playing around with small models - ‘cause like, you start small! You don’t wanna start with the biggest and most complicated thing. You start with the smallest thing, and you’re looking at it and you go, “Wait a second. This runs really fast.”
It was sort of a surprise to me. I thought I would need a big GPU. I thought things would be expensive. I thought it was always, you know, GPT, you know, 2x H200s or whatever, and then you just see the run times and you’re like, “Wait a second, like, economics may make sense here.”
Tommy: Can you remind me of the model size?
Durst: Yeah, 5.4 million parameters, 21 megs...
Tommy: That’s nothing… *laughs*, that’s nothing!
Durst: And the serving is just TorchScript. Essentially, PyTorch has a default, like, way to serve these things for call-out from C++. Like, there are significantly more optimized serving frameworks that [we] could’ve explored.

Closing
As we wrap up, it’s worth reminding everyone that while this is an impressive application, it’s not ready to ship into Counter-Strike just yet. MLMove currently is only built to handle retakes for Dust 2. In order for this to be shippable, it would need to be trained for every game mode in every map: a challenge that perhaps is attainable for an entire dev team, but not necessarily for a single PhD student.
Durst, of course, has since graduated and is off in the working world, but he still has some ideas of his own of where this project could go next.
Tommy: There’s a huge amount of scope for this, and no doubt you’re, on one hand, like, happy that this is done, but also itching to come back to it? What are the things you would love to pursue if you had time, and what are the things someone else should go and do with this research?
Durst: So I think inspecting sort of the details of the model would be a great way for someone to get started.
You know, when is the attention good? When is the attention bad? When does this lead to good teamwork? When does this lead to bad teamwork? How do I fight with the inertia problem? I think the inertia problem is, like, a really hard problem that I, I’m sure other people in academia have addressed better than I, and I think, that would be a problem that would be important to solve, and sort of inspecting the attention mask and visualizing that as this coaching framework would be very cool.
What I am interested in - and this is sort of what we address in the end of the dissertation - is essentially, the way we evaluated this, separate from the user study, was looking for expert terms. Things like pushing or saving, There’s a rich culture of expert terms describing how people play, and these can be thought of as long-term plans.
So I have a model that does, like, short-term movement, but sort of the way we think about a lot of games is that we’ve invented a language for each game to describe it. Thinking about, well, what does that terminology look like, sort of going back to my programming languages background, and thinking about what does it mean to have, a good language for describing behaviour? Uh, and particularly then once you have this language of behavior, will we have these amazing long-term language models that maybe shouldn’t be running in the loop. But, you know, how do we connect these movement models to language?
And then once you have that, you know, we not, we’re living in the age of NLP, you know? We’re living in the age of language. Why don’t we take these amazing tools that are the big boy transformers and see how they might be used, connected to one of these models?
A big thank you to David Durst for his time being interviewed for this episode of AI and Games. Please consult the materials in the Related Reading below to find out more about the project.

Related Reading
Durst et al, 2024: Learning to Move Like Professional Counter-Strike Players, Symposium on Computer Animation (SCA), 2024
Ngiam et al. 2022: Scene Transformer: A Unified Architecture for Predicting Multiple Agent Trajectories, International Conference on Learning Representations 2022
As detailed in the original paper, the work on the transformer is inspired by this work on a ‘Scene Transformer’ by Ngiam et al.